Playwright vs Puppeteer: The Differences
Flipnode on Apr 27 2023

Over the years, end-to-end testing for modern browsers has made significant strides, and there are now high-level API controls that enable automated testing for web applications. With the help of specific applications, almost everything that a user can perform manually can also be accomplished using automated testing tools. Among the most popular tools for web automation are Playwright and Puppeteer. While both tools are similar in their approach to web automation, there are distinct differences between them that can impact their effectiveness in certain scenarios, such as web scraping. In this regard, it is essential to understand and compare Playwright and Puppeteer to determine which tool is best suited for a particular use case. By examining their differences and similarities, we can make an informed decision about which tool to use for specific automation tasks, including web scraping.
The basics
Playwright and Puppeteer are two Node.js libraries that allow for headless browser control, making them essential for web testing and browser automation. While they share several similarities, they also have some critical differences.
Developed by Microsoft, Playwright offers both asynchronous and synchronous client implementations and has cross-language and cross-browser support. Its capabilities include web automation, web testing, and web scraping, making it a versatile tool for developers.
Puppeteer, on the other hand, was developed by Google, and boasts a powerful implementation of Chrome DevTools Protocol. This enables it to provide a user-friendly API to control Chromium-based environments. Its features include page automation, network monitoring, and PDF generation, which make it an excellent option for web developers.
When it comes to web automation, both tools have proven to be reliable and efficient, but they have different use cases. In terms of web scraping, Playwright provides better support for other browsers like Firefox and Safari, while Puppeteer is known for its excellent compatibility with Chromium-based browsers. In conclusion, developers must assess their needs and choose the tool that best suits their particular project requirements.
The competitive background
In retrospect, the developers at Chrome introduced Puppeteer in 2017 as a response to Selenium's inconsistent behavior in browser automation. However, soon after, the two lead developers of Puppeteer migrated from Google to Microsoft to develop a new solution called Playwright. As a result, Playwright and Puppeteer are highly comparable, sharing similarities in API methods, browser automation, and even web scraping capabilities.
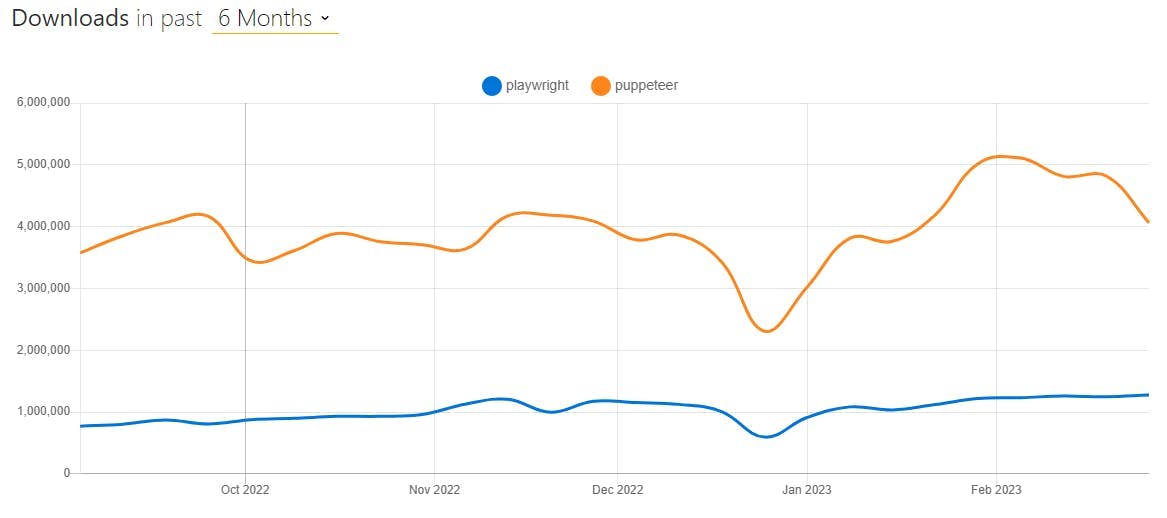
As of January 2023, Puppeteer appears to be the more popular option between the two, as shown by the graph above. This is not surprising, considering that Puppeteer was released earlier than Playwright, which is a newer Node.js library introduced in January 2020.
Playwright and Puppeteer in web scraping
Automated data extraction from websites is commonly known as web scraping. Both Playwright and Puppeteer have similar web scraping capabilities, where they can automate web page interactions, such as button clicks, form filling, and page scrolling to extract target data.
Despite using actual browsers, it is possible to distinguish whether a browser is controlled by a real user or an automation toolkit. One of the frequent issues with web scraping is bot detection leading to blocking from websites, which can be avoided by setting breaks between sequential activities.
Playwright's auto-waiting function imitates a human user by waiting a specific amount of time after filling out a login form before clicking a button. On the other hand, Puppeteer lacks convenience in this aspect as you would have to set up timers manually using the Page.waitForSelector() method. However, multiple timers can slow down browsing, and some websites can detect them.
Both Playwright and Puppeteer are susceptible to being blocked when web scraping. To collect data without interruption, third-party services like proxies or AI-based solutions are required to bypass CAPTCHAs using advanced browser fingerprinting.
Playwright supports asynchronous clients for scaling up performance and synchronous clients for simple script convenience, whereas Puppeteer only supports asynchronous clients. Playwright's cross-browser support is one of its significant advantages, making it a preferred choice for projects requiring data scraping from multiple browsers.
Although Puppeteer is a general-purpose browser automation client, it has official support for web scraping issues. Still, Playwright has a slight edge in functionality for web scraping due to its abundance of supplementary features.
The differences
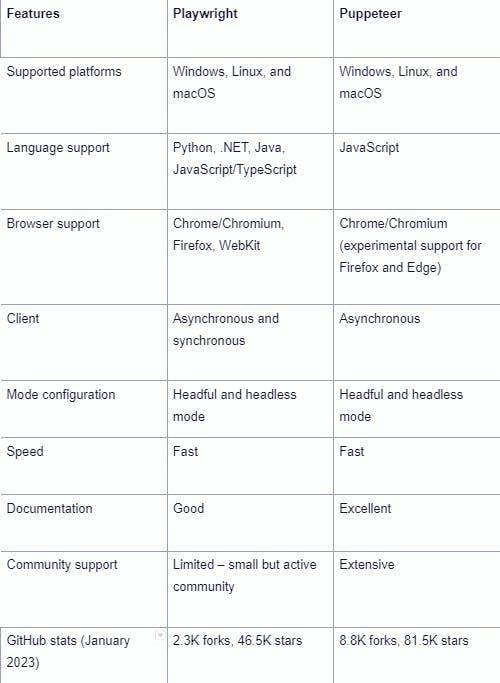
The table below highlights the primary distinctions between the two tools, including language, browser, community support, and documentation, which are the main factors that set them apart.
Browser support
Web scraping is the process of extracting data from websites automatically. Both Playwright and Puppeteer libraries have similar core functionality when it comes to web scraping. They can automate web page interactions such as clicking buttons, filling out forms, and scrolling through pages to extract target data.
However, even though both tools use actual browsers, it's still possible to determine whether the interaction is controlled by a real user or automated by an automation toolkit. A frequent issue with web scraping is bot detection, resulting in websites blocking the user or the automated app when it sends an unreasonable amount of requests to the host server. To avoid these blocks, setting breaks between sequential activities is one of the solutions.
Playwright’s auto-waiting function imitates a human user by waiting for a certain amount of time before clicking a button. This feature is not as convenient in Puppeteer, as one would have to set up timers manually using, for example, the Page.waitForSelector() method. However, having multiple timers has the drawback of slowing down browsing, and some websites can still detect them.
Both Playwright and Puppeteer can be integrated with a plethora of auxiliary tools for interruption-free data collection. Third-party services such as proxies or AI-based solutions can bypass CAPTCHAs by using advanced browser fingerprinting. Playwright supports asynchronous clients for additional performance scaling and synchronous clients for simple script convenience. In contrast, Puppeteer only supports asynchronous clients. With Playwright, it is possible to write small scrapers using a synchronous client and scale up easily by switching to a more complex asynchronous architecture
Community support and documentation
Despite being a relatively new addition to the browser automation tool scene, Playwright has made significant strides in a short amount of time. However, due to its relative novelty, the level of community support and available resources for Playwright may not be as extensive as those for Puppeteer. Nonetheless, Playwright has gained a dedicated following and is continuously expanding its resources, with more and more users and developers contributing to its growth. As such, while Puppeteer may currently have a more established community, it is worth keeping an eye on Playwright's progress and development as it may continue to grow and gain more support in the future
Language support
Playwright offers a wider range of language support for developers, including Python, Java, JavaScript, TypeScript, and .NET. This broad support enables developers to use their preferred programming language for test automation. On the other hand, Puppeteer only supports JavaScript, with an unofficial Python port called Pyppeteer. This limitation could hinder developers who prefer using other programming languages, especially if they are not proficient in JavaScript. By offering multiple language support, Playwright provides more flexibility and accessibility for developers of varying skill sets and backgrounds.
Conclusion
In summary, when it comes to web automation and web scraping, both Puppeteer and Playwright are powerful libraries to consider. However, Playwright stands out with its multiple browser support and cross-language capabilities, which make it a more versatile and robust solution. Additionally, Playwright offers multi-context browsing and supports browser extensions, further enhancing its capabilities for web automation.
That said, Puppeteer has its strengths as well. For instance, it benefits from a well-established community, excellent documentation, and a more mature ecosystem. Hence, if you are working on a project that requires extensive peer guidance, or if you are only working with Chrome, Puppeteer may be the better choice. Also, if you are working with a limited time frame, Puppeteer may help you get the job done faster.
Finally, if you already have developers familiar with one of the tools on board, it may not be wise to migrate to the other, regardless of the advantages. Familiarity with the tool plays a significant role in decision-making when it comes to choosing between Playwright and Puppeteer. Ultimately, it is essential to evaluate your project's specific requirements and choose the tool that best fits your needs



