How to Parse HTML with PyQuery: Python Tutorial
Flipnode on Apr 24 2023

PyQuery is a powerful Python library that enables users to efficiently manipulate and extract data from HTML and XML documents. Its syntax and API are similar to jQuery, making it a convenient tool for web content manipulation in Python.
Using CSS selectors, PyQuery lets you select specific elements from an XML or HTML document and extract or modify data from them. This feature makes PyQuery highly valuable for XML and HTML manipulation, parsing, and data extraction from web APIs.
If you're interested in writing a web scraper in Python, PyQuery is an excellent library to use. In this article, we will cover the basics of using PyQuery and compare it with Beautiful Soup, another popular web scraping library in Python.
With PyQuery, you can quickly and easily scrape web pages, retrieve information from APIs, and extract data for analysis or storage. It's intuitive syntax and flexibility make it an excellent choice for web scraping and data manipulation in Python.
So whether you're a seasoned developer or just starting with web scraping, PyQuery is a valuable addition to your Python toolkit. Follow along as we explore its capabilities and show you how to use it effectively for your web scraping needs.
How to install PyQuery
Before installing PyQuery, you must ensure that Python is installed on your device. If you do not have Python, you can download it from the official Python website and install it. For this tutorial, we will be using Python 3.10.7 and PyQuery 2.0.0.
To begin, we will install the PyQuery library using pip. You can do this by opening a terminal or command prompt and entering the following command:
python -m pip install pyquery
Alternatively, if you want to install a specific version of the PyQuery library, you can use the following command:
python -m pip install pyquery==2.0.0
This command will install PyQuery along with any necessary dependencies. If you encounter any issues during the installation process, you can refer to the official PyQuery documentation for assistance.
Parsing DOM
Let's begin by using PyQuery to parse the Document Object Model (DOM) and create our first scraper. First, we need to import the necessary libraries - requests and PyQuery:
import requests
from pyquery import PyQuery as pq
Now, we will use the requests module to fetch an HTML page and parse it using PyQuery. In this example, we will fetch the website "https://example.com" and extract the title using PyQuery:
response = requests.get("https://example.com")
doc = pq(response.content)
print(doc("title").text())This code will print the title of the website. We first use the get() method to fetch the content of the website. Next, we use the PyQuery class to parse the content and store it in the doc object. Finally, we use the CSS selector to extract and print the title text using the title tag as a CSS selector.
Extracting multiple elements using CSS selector
In this example, we'll demonstrate how to extract multiple HTML elements using the CSS Selector from the "https://books.toscrape.com website". PyQuery offers in-built support to extract an HTML document from a URL. Here's how you can implement it:
from pyquery import PyQuery as pq
doc = pq(url="https://books.toscrape.com")
for link in doc("h3 > a"):
print(link.text(), link.attrib["href"])
We use the CSS Selector to select all the links inside the H3 tags. Then, using a for loop, we print the text and URL of those links. Depending on the number of elements, the CSS Selector may return one or more elements.
To access the element properties, we use the attrib object, which is similar to a Python dictionary. We pass the "href" as a key, and it returns the URL of the element.
Removing elements
In certain situations, we may need to eliminate certain elements from the DOM that are not needed. PyQuery provides a method named remove() to achieve this goal.
For instance, if we want to remove all the icons from the webpage in the preceding example, we can use the following code:
from pyquery import PyQuery as pq
doc = pq(url="https://books.toscrape.com")
doc("i").remove()
print(doc)
After executing this code, it will erase all the icons from the document object model.
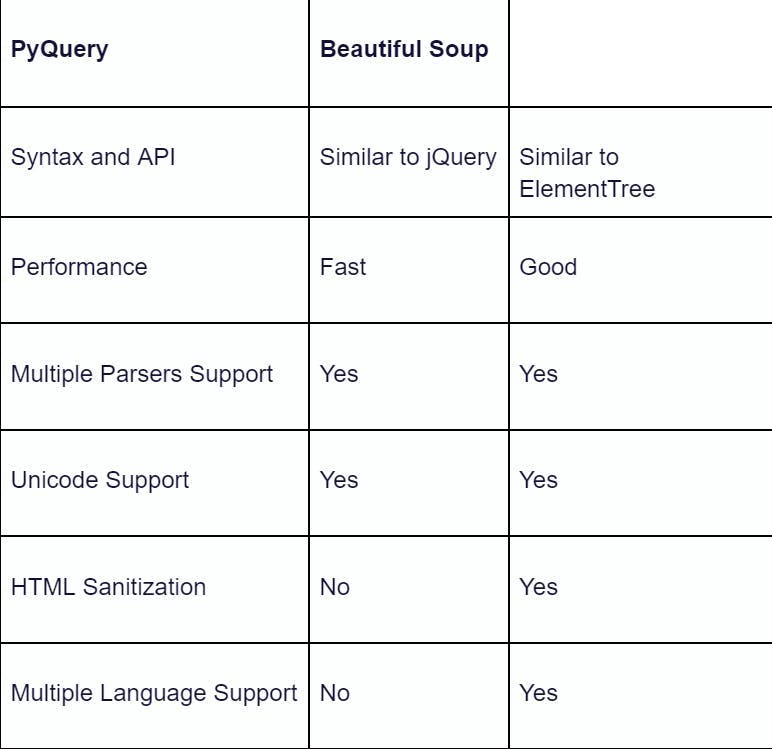
PyQuery vs. BeautifulSoup
Both PyQuery and Beautiful Soup are powerful Python libraries for working with HTML and XML documents, enabling parsing, traversing, and manipulating these types of documents, as well as extracting data from web pages and APIs.
However, PyQuery and Beautiful Soup differ in their syntax and API. PyQuery has a syntax and API that is similar to the jQuery JavaScript library, designed for working with HTML and DOM elements. If you already know how to make jQuery queries, you should find PyQuery easy to learn. On the other hand, Beautiful Soup has a different syntax and API that is more similar to the ElementTree library in Python's standard library. If you're familiar with ElementTree, you may find Beautiful Soup more intuitive to use. Additionally, Beautiful Soup offers built-in HTML sanitization, which is useful when scraping websites with broken HTML. As a result, Beautiful Soup is often preferred for Python web scraping tasks due to its feature-richness.
Despite this, PyQuery is lightweight and can perform tasks faster than Beautiful Soup. To test the response times of Beautiful Soup and PyQuery, among other similar libraries, you can use the code available in this GitHub gist.
Ultimately, the choice between PyQuery and Beautiful Soup depends on your specific requirements and preferences. Both can be excellent choices for working with HTML and XML files in Python.
Wrapping up
In conclusion, PyQuery is a user-friendly Python library that facilitates working with HTML and XML documents. Its jQuery-like syntax and API make parsing, traversing, and manipulating HTML and XML documents as well as extracting data, a straightforward process.
Although PyQuery is a robust tool, there are other Python libraries available for handling HTML and XML documents. Beautiful Soup is an alternative library that provides a different syntax and API, making it suitable for different use cases. Ultimately, the choice between PyQuery and Beautiful Soup is based on individual needs and preferences.
We hope this article has provided you with valuable insights and enhanced your ability to utilize PyQuery in your projects.



